Benefiting from large-scale pre-trained text-to-image (T2I) generative models, impressive progress has been achieved in customized image generation, which aims to generate user-specified concepts. Existing approaches have extensively focused on single-concept customization and still encounter challenges when it comes to complex scenarios that involve combining multiple concepts. These approaches often require retraining/fine-tuning using a few images, leading to time-consuming training processes and impeding their swift implementation. Furthermore, the reliance on multiple images to represent a singular concept increases the difficulty of customization.
To this end, we propose FreeCustom, a novel tuning-free method to generate customized images of multi-concept composition based on reference concepts, using only one image per concept as input. Specifically, we introduce a new multi-reference self-attention (MRSA) mechanism and a weighted mask strategy that enables the generated image to access and focus more on the reference concepts. In addition, MRSA leverages our key finding that input concepts are better preserved when providing images with context interactions. Experiments show that our method's produced images are consistent with the given concepts and better aligned with the input text. Our method outperforms or performs on par with other training-based methods in terms of multi-concept composition and single-concept customization, but is simpler.
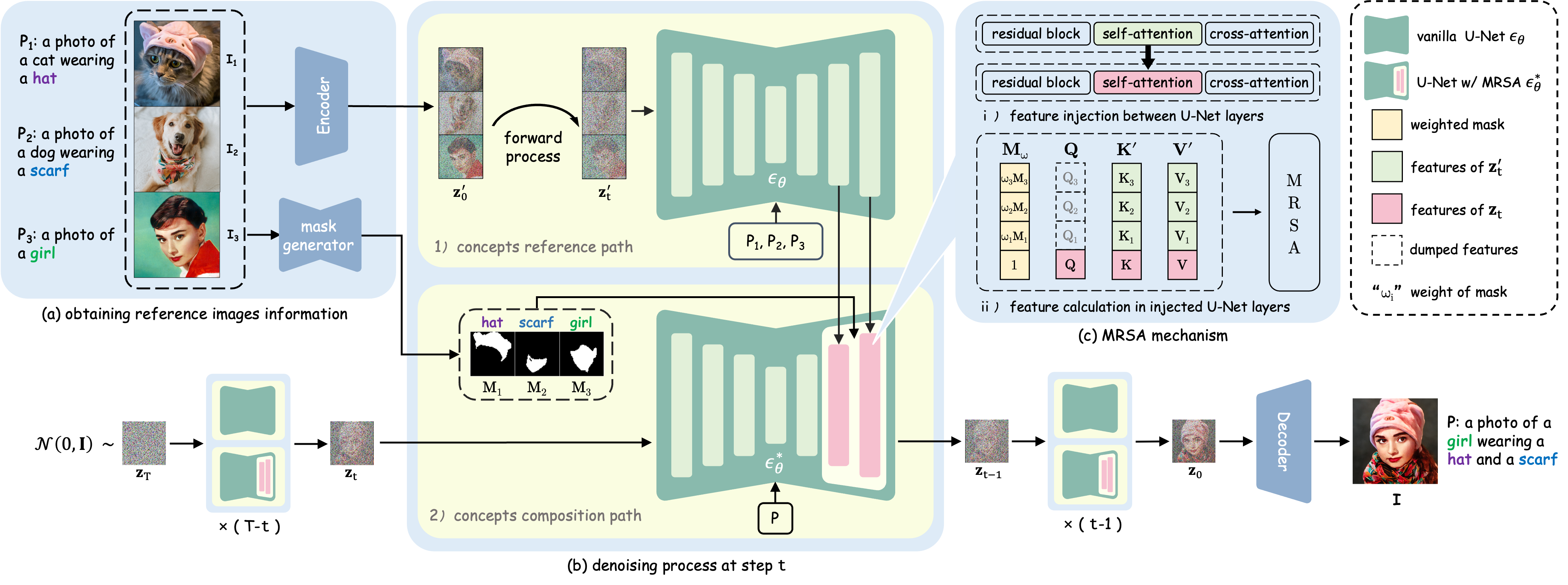
Given a set of reference images $ \mathcal{I} = \{I_1, I_2, I_3\} $ and their corresponding prompts $\mathcal{P} = \{P_1, P_2, P_3\}$, we generate a multi-concept customized composition image $I$ aligned to the target prompt $P$. (a) We use a VAE encoder to convert reference images into the latent representation $\mathbf z_0'$ and a segmentation network to extract masks of the concepts. (b) The denoising process involves two paths: 1) the concepts reference path and 2) the concepts composition path. In 1), we employ a diffusion forward process to transform $\mathbf z_0'$ into $\mathbf z_t'$, subsequently passing $\mathbf z_t'$ to the U-Net $\epsilon_\theta$. Notably, the output of $\epsilon_\theta$ isn't used. In 2), we initially sample $\mathbf z_T \sim \mathcal{N} (0,\textbf{I})$ and iteratively denoise the latent until we obtain $\mathbf z_0$. At each time step $t$, we directly transmit the current latent $\mathbf z_t$ to the modified U-Net $\epsilon_\theta^*$ and employ the MRSA to integrate the features from the last two blocks of both the U-Net $\epsilon_\theta$ and the U-Net $\epsilon_\theta^*$. Finally, we utilize a VAE decoder to convert $\mathbf{z_0}$ into the final image $I$. (c) The MRSA mechanism. i) Feature injection happens in the self-attention module between U-Net layers, ii) we apply MRSA machenism using $$ {\rm MRSA} (\mathbf{Q}, \mathbf{K}', \mathbf{V}',\mathbf{M}_w) = {\rm Softmax} (\frac{\mathbf{M}_w \odot (\mathbf{Q} \mathbf{K}'^T)}{\sqrt{d}}) \mathbf{V}'.$$
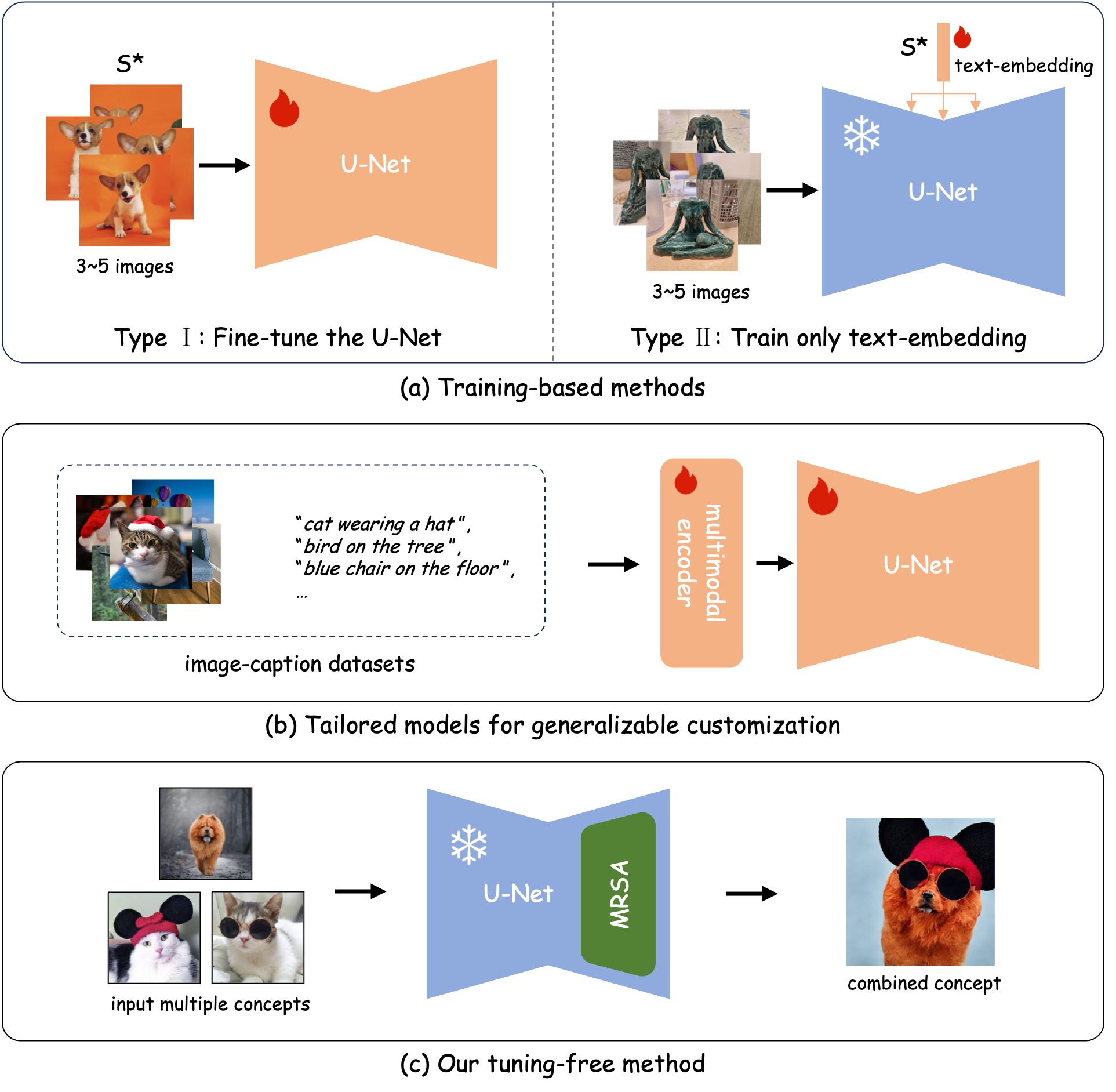
Previous methods for customization can be categorized into two main categories: (a) training-based methods and (b) tailored models for generalizable customization. Training-based methods often involve fine-tuning an entire model (Type Ⅰ) or learning a text embedding to represent a specific subject (Type Ⅱ). Tailored models typically require re-training on large-scale image datasets to establish a versatile foundation. Unlike these two types of methods, our approach can directly generate customized images of multi-concept combinations without any additional training.

Comparisons of multi-concept composition.

Comparisons of single-concept customization.
Single-concept customization. Our method enables extensive customization of a single concept by inputting a single image
Our method generates objects with similar appearance and materials as the input image.

(a) BLIP Diffusion with Ours.

(b) ControlNet with Ours.
Our method can enhance ControlNet and BLIP Diffusion in a plug-and-play manner. (a) By using our method, the output of BLIP diffusion becomes more faithful to the input image and better aligned with the input text. (b) Furthermore, ControlNet can generate results that are consistent in layout and identity when combined with ours.
@inproceedings{ding2024freecustom,
title={FreeCustom: Tuning-Free Customized Image Generation for Multi-Concept Composition},
author={Ganggui Ding and Canyu Zhao and Wen Wang and Zhen Yang and Zide Liu and Hao Chen and Chunhua Shen},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
year={2024}
}

