CVPR 2026
Exploring Spatial Intelligence
Exploring Spatial Intelligence
from a Generative Perspective
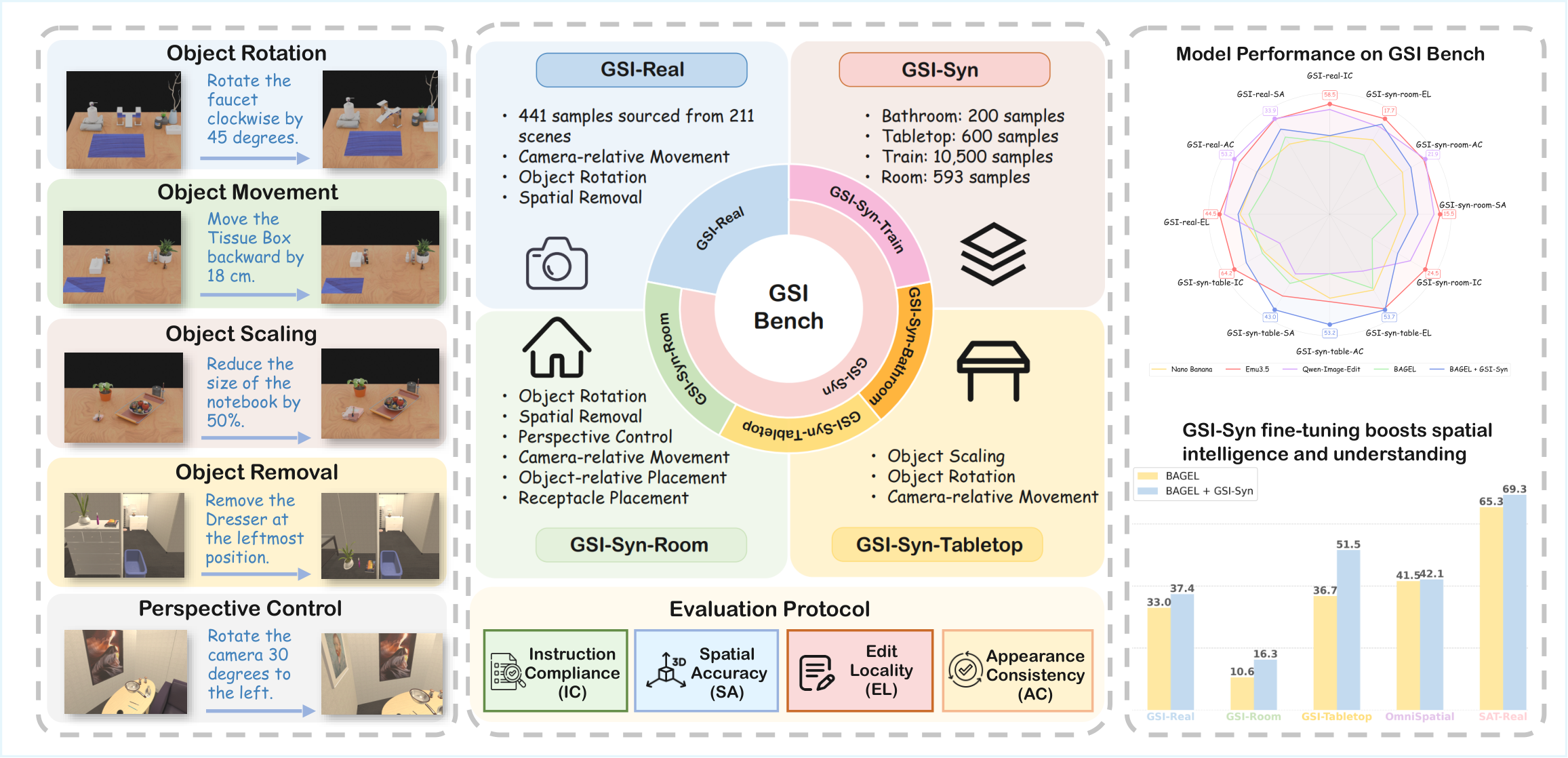
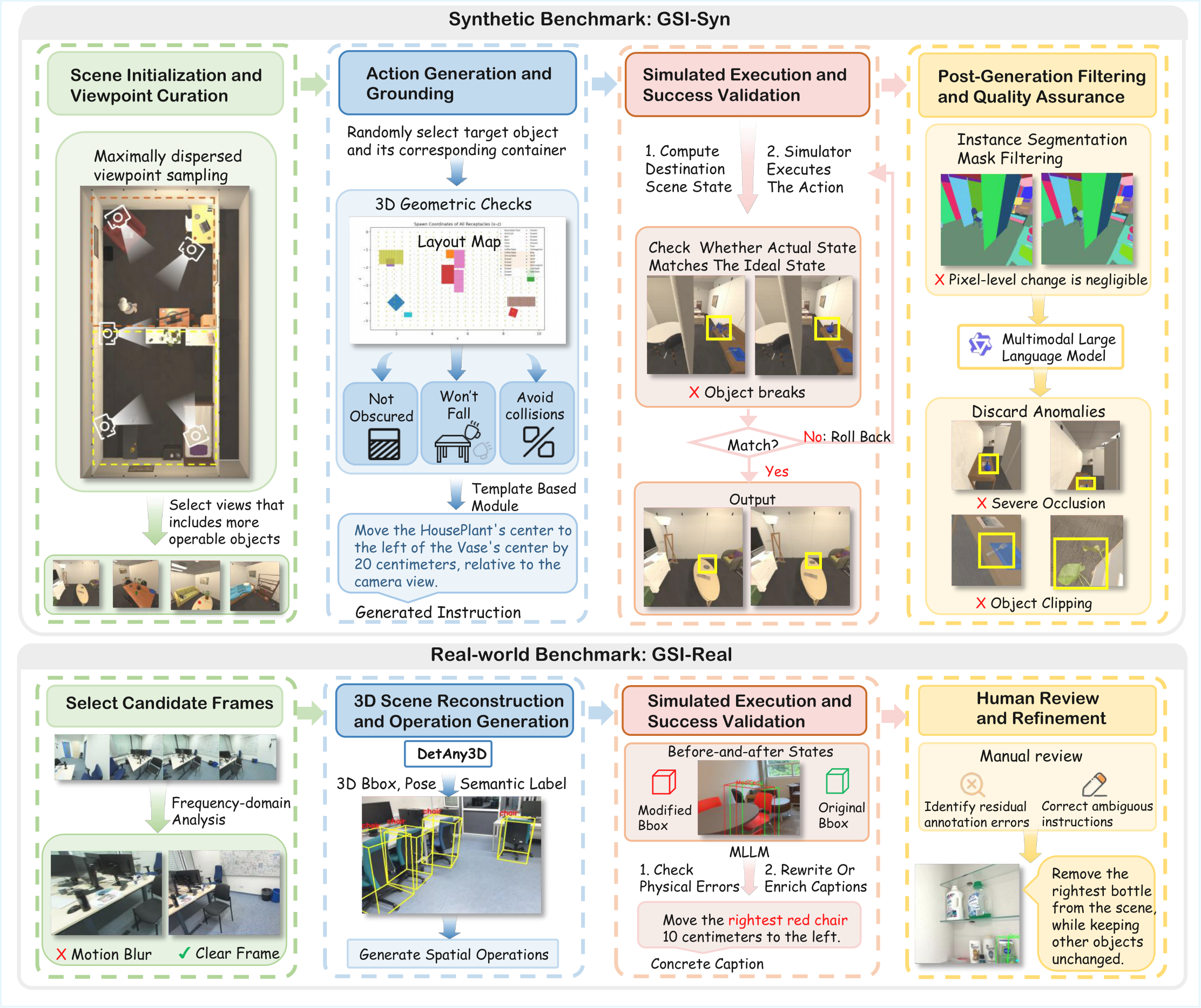
GSI-Bench — a benchmark and training set for Generative Spatial Intelligence,
spanning real-world (GSI-Real) and large-scale synthetic (GSI-Syn) settings.
1Zhejiang University, State Key Laboratory of CAD & CG ·
2Ant Group ·
3Westlake University ·
4Zhejiang University of Technology
*Equal contribution †Corresponding authors
*Equal contribution †Corresponding authors