Quantitative Results
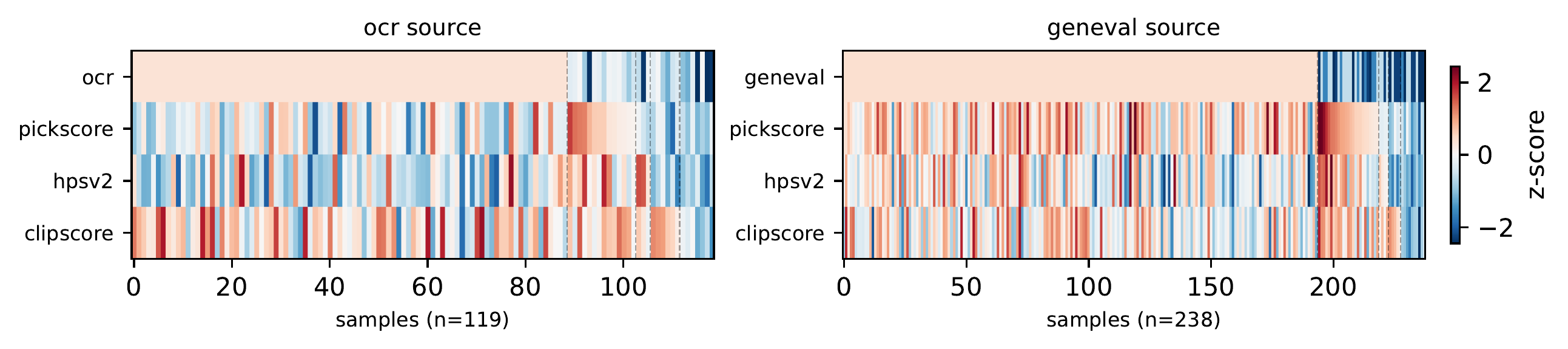
SD3.5 Medium fine-tuned with five rewards: PickScore, CLIPScore, HPSv2.1, OCR, and GenEval. Green rows are RL fine-tunes; gray cells are in-domain rewards used during training.
| Model |
Rule-Based |
Model-Based |
Composite ↑ |
| GenEval | OCR |
PickScore | CLIPScore | HPSv2.1 |
Aesthetic | ImgRwd | UniRwd |
| SD-XL | 0.55 | 0.14 | 22.42 | 0.287 | 0.280 | 5.60 | 0.76 | 2.93 | −0.46 |
| SD3.5-L | 0.71 | 0.68 | 22.91 | 0.289 | 0.288 | 5.50 | 0.96 | 3.25 | +0.12 |
| FLUX.1-Dev | 0.66 | 0.59 | 22.84 | 0.295 | 0.274 | 5.71 | 0.96 | 3.27 | +0.10 |
| SD3.5-M (w/o CFG) | 0.24 | 0.12 | 20.51 | 0.237 | 0.204 | 5.13 | −0.58 | 2.02 | −2.32 |
| SD3.5-M + CFG | 0.63 | 0.59 | 22.34 | 0.285 | 0.279 | 5.36 | 0.85 | 3.03 | −0.26 |
| + FlowGRPO (GenEval) | 0.95 | 0.66 | 22.51 | 0.293 | 0.274 | 5.32 | 1.06 | 3.18 | +0.12 |
| + FlowGRPO (OCR) | 0.66 | 0.92 | 22.41 | 0.290 | 0.280 | 5.32 | 0.95 | 3.15 | +0.01 |
| + FlowGRPO (PickScore) | 0.54 | 0.68 | 23.50 | 0.280 | 0.316 | 5.90 | 1.29 | 3.37 | +0.36 |
| + DiffusionNFT (sequential)† | 0.94 | 0.91 | 23.80 | 0.293 | 0.331 | 6.01 | 1.49 | 3.49 | +1.02 |
| + DiffusionNFT (weighted-sum)‡ | 0.92 | 0.91 | 21.53 | 0.267 | 0.300 | 6.15 | 1.16 | 3.04 | +0.18 |
| + MARBLE (ours) | 0.94 | 0.96 | 22.83 | 0.286 | 0.355 | 6.59 | 1.53 | 3.52 | +1.12 |
Bold = best, underline = second best.
Composite is the per-row mean of column-wise z-scores
(each metric standardized to zero mean and unit variance across the rows of the table)
and aggregates performance over all eight metrics; higher is better.
Reading: MARBLE achieves the best score on OCR, HPSv2.1, Aesthetic,
ImageReward, and UniReward — five out of eight metrics — in a
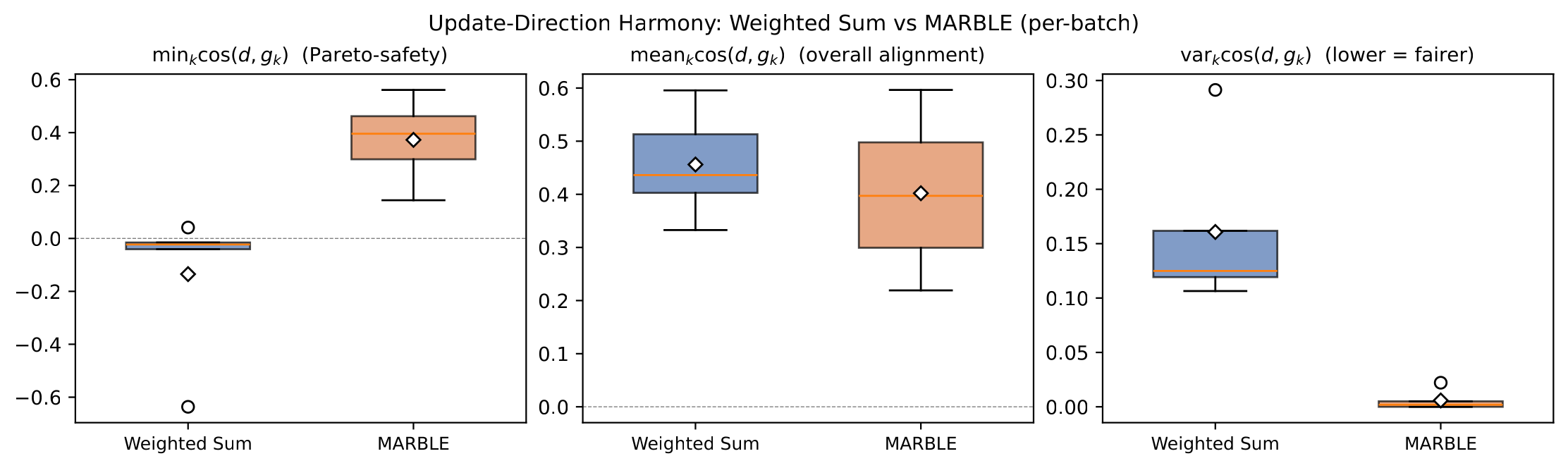
single model, and the highest Composite score overall. The weighted-sum baseline
collapses on PickScore and CLIPScore, while sequential training matches MARBLE only by
training in stages with a hand-crafted curriculum.
†Sequential multi-stage training. ‡Single-run weighted-sum aggregation.
Training Cost
Measured on 8×H200 with five rewards (K = 5).
Speed and memory are normalized by the weighted-sum DiffusionNFT baseline.
Amortization (N = 10) brings full per-reward harmonization
from 0.56× back to 0.97× the baseline throughput,
with only a 1.14× memory bump.
| Method |
Relative speed ↑ |
GPU memory |
| Weighted Sum (DiffusionNFT, K = 5) | 1.00× | 59 GB (1.00×) |
| MARBLE w/o amortization (K = 5) | 0.56× | 67 GB (1.14×) |
| MARBLE w/ amortization (K = 5, N = 10) | 0.97× | 67 GB (1.14×) |
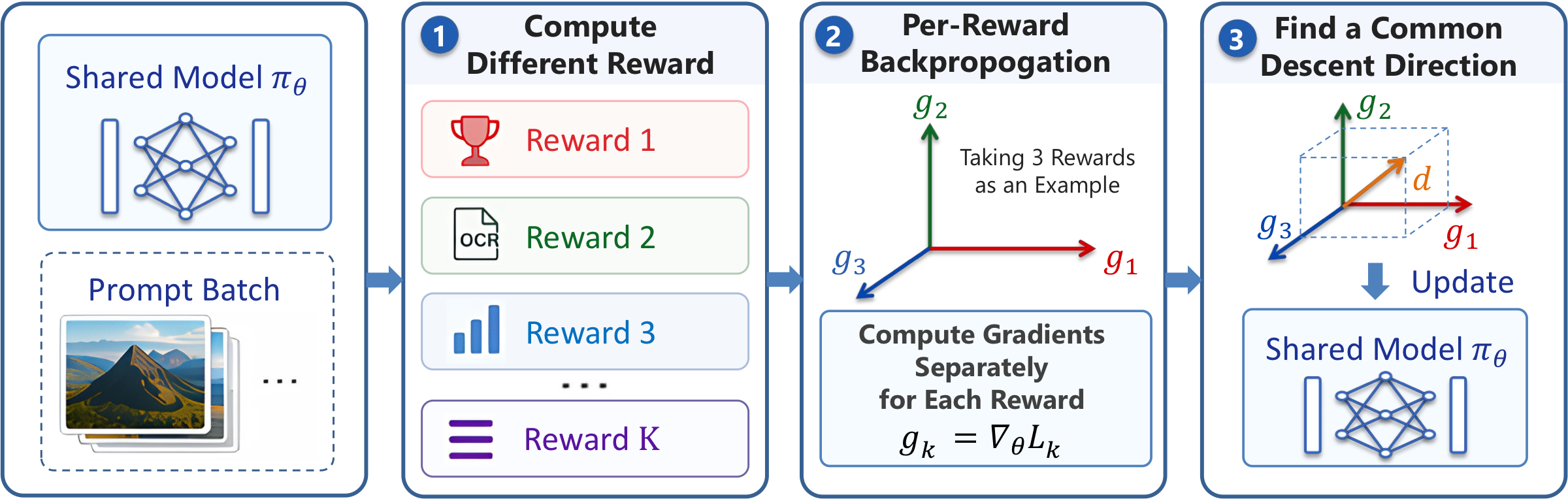
Reading: per-reward gradient harmonization at every step costs $K{+}1$ backward
passes, dropping throughput to $0.56\times$. Amortizing the full MGDA solve over
$N{=}10$ steps reduces the average per-step cost to $(K{+}N)/N \approx 1.5\times$
backward passes — nearly recovering single-reward training speed at no quality
cost (see Quantitative Results above and the EMA decay $\rho$ ablation below).